LLMs have three major components: a massive database of “relatedness” (how closely related the meaning of tokens are), a transformer (figuring out which of the previous words have the most contextual meaning), and statistical modeling (the likelihood of the next word, like what your cell phone does.)
LLMs don’t have any capability to understand spelling, unless it’s something it’s been specifically trained on, like “color” vs “colour” which is discussed in many training texts.
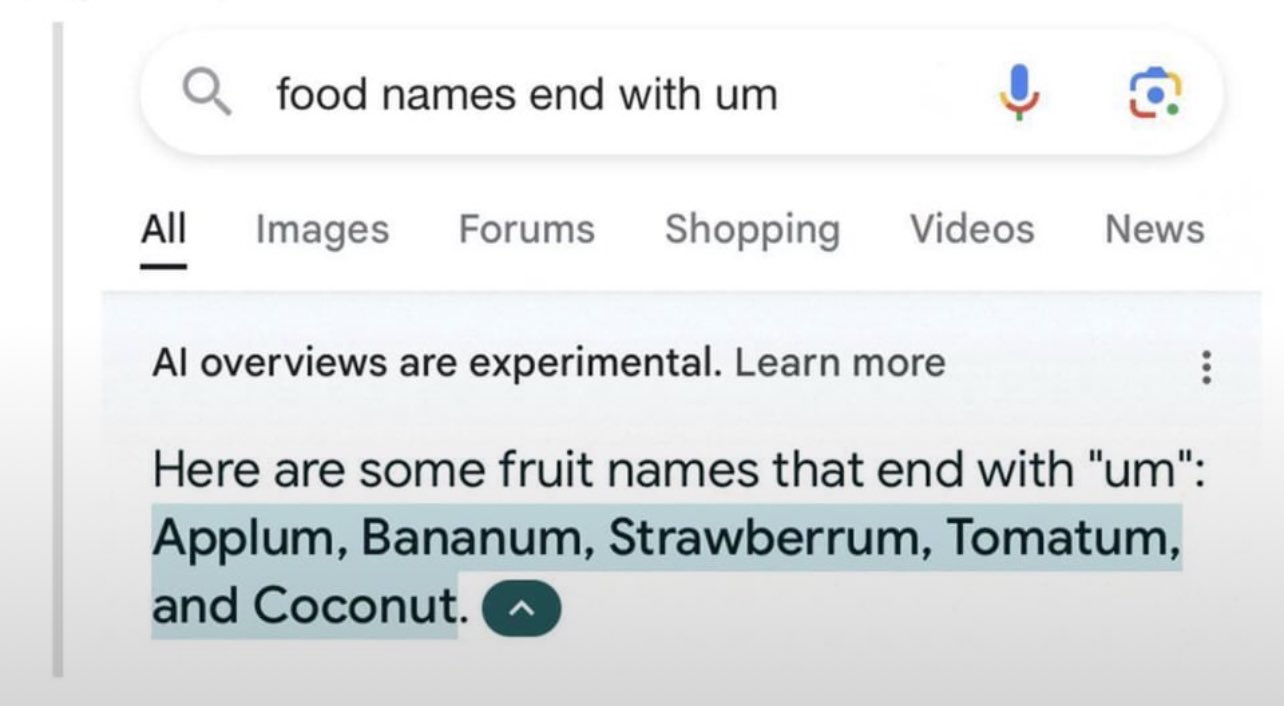
"Fruits ending in ‘um’ " or "Australian towns beginning with ‘T’ " aren’t talked about in the training data enough to build a strong enough relatedness database for, so it’s incapable of answering those sorts of questions.
It can’t see what tokens it puts out, you would need additional passes on the output for it to get it right. It’s computationally expensive, so I’m pretty sure that didn’t happen here.

{kind=link}
It’s crazy how bad d AI gets of you make it list names ending with a certain pattern. I wonder why that is.
LLMs aren’t really capable of understanding spelling. They’re token prediction machines.
LLMs have three major components: a massive database of “relatedness” (how closely related the meaning of tokens are), a transformer (figuring out which of the previous words have the most contextual meaning), and statistical modeling (the likelihood of the next word, like what your cell phone does.)
LLMs don’t have any capability to understand spelling, unless it’s something it’s been specifically trained on, like “color” vs “colour” which is discussed in many training texts.
"Fruits ending in ‘um’ " or "Australian towns beginning with ‘T’ " aren’t talked about in the training data enough to build a strong enough relatedness database for, so it’s incapable of answering those sorts of questions.
It can’t see what tokens it puts out, you would need additional passes on the output for it to get it right. It’s computationally expensive, so I’m pretty sure that didn’t happen here.
doesn’t it work literally by passing in everything it said to determine what the next word is?
it chunks text up into tokens, so it isn’t processing the words as if they were composed from letters.