- cross-posted to:
- learn_programming@programming.dev


{kind=link}
cross-posted from: https://programming.dev/post/6660679
It’s about asking, “how does this algorithm behave when the number of elements is significantly large compared to when the number of elements is orders of magnitude larger?”
Big O notation is useless for smaller sets of data. Sometimes it’s worse than useless, it’s misguiding. This is because Big O is only an estimate of asymptotic behavior. An algorithm that is O(n^2) can be faster than one that’s O(n log n) for smaller sets of data (which contradicts the table below) if the O(n log n) algorithm has significant computational overhead and doesn’t start behaving as estimated by its Big O classification until after that overhead is consumed.
#computerscience
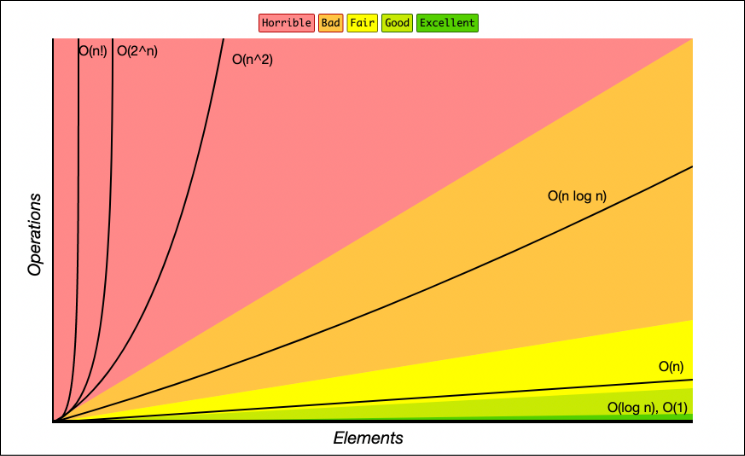
Image Alt Text:
"A graph of Big O notation time complexity functions with Number of Elements on the x-axis and Operations(Time) on the y-axis.
Lines on the graph represent Big O functions which are are overplayed onto color coded regions where colors represent quality from Excellent to Horrible
Functions on the graph:
O(1): constant - Excellent/Best - Green
O(log n): logarithmic - Good/Excellent - Green
O(n): linear time - Fair - Yellow
O(n * log n): log linear - Bad - Orange
O(n^2): quadratic - Horrible - Red
O(n^3): cubic - Horrible (Not shown)
O(2^n): exponential - Horrible - Red
O(n!): factorial - Horrible/Worst - Red"
You must log in or register to comment.

Yup, it’s why O(N+10) and even O(2N) are effectively the same as O(N) on your CS homework. Speaking too generally, once you’re dithering over the efficiency of an algorithm processing a 100-item dataset you’ve probably gone too far in weeds. And optimizations can often lead to messy code for not a lot of return.
That’s mostly angled at new grads (or maybe just at me when I first started). You’ve probably got bigger problems to solve than shaving a few ms from the total runtime of your process.
Just a little nitpicking, O(N+10) and O(2N) are not “effectively” the same as O(N). They are truly the same.

This is why I only use bogo sort
With a small enough data set, bogo sort will perform just as well as an O(1) algorithm for sorting for both ascending and descending order!
That’s using your noodle!
Use it or lose it, right?

Aren’t the most commonly accepted sorting algorithms O(nlog(n))? Quicksort? Mergesort? Those are considered bad?

I mean, it is entirely reasonable that “bad” is the best performance you can hope for while sorting an entire set of generally comparable items.
If you can abuse special knowledge about the data being sorted then you can get better performance with things like radix sort, but in general it just takes a lot of work to compare them all even if you are clever to avoid wasted effort.
Yeah, you’re right, it doesn’t make sense to say that O(f(n)) is good or bad for any algorithm. It must be compared to the complexity of other algorithms which solve the same problem in the same conditions.
I mean…yeah. Just because something is provably the best possible thing, doesn’t mean it’s good. Sorting should be avoided if at all possible. (And in many cases, such as with numbers, you can do better than comparison-based sorts)
The labels are from the perspective of viewing the space of all possible functions of element set size to operations, so they don’t apply to any particular problem an algorithm is attempting to solve (that space is often smaller).

There’s some simple rules of thumb that can be inferred from Big O notation. For example, I try to be careful with what I do in nested loops whose number of repetitions will grow with application usage. I might be stepping into O(n^2) territory, this is not the place for database queries.

TFW you’re storing 2D and 3D data structures and you read this 😂
I don’t see the contradiction. If you’re doing CRUD operations on 10,000 points, I’m sure you’re doing what’s possible to send it to storage in one fell swoop. You most probably get out of those loops any operation that doesn’t need to be repeated as well.
I’ve been wrong about the performance of algorithms on tiny data sets before. It’s always best to test your assumptions.

god i wish i had this image when i was learning algorithms. i always just guessed for some of the exam questions 🙃