
In the What are YOU self-hosting? thread, there are a lot of people here who are self-hosting a huge number of applications, but there’s not a lot of discussion of the platform these things run on.
What does your self-hosted infrastructure look like?
Here are some examples of more detailed questions, but I’m sure there are plenty more topics that would be interesting:
- What hardware do you run on? Or do you use a data center/cloud?
- Do you use containers or plain packages?
- Orchestration tools like K8s or Docker Swarm?
- How do you handle logs?
- How about updates?
- Do you have any monitoring tools you love?
- Etc.
I’m starting to put together the beginning of my own homelab, and I’ll definitely be starting small but I’m interested to hear what other people have done with their setups.

At home I have a Proxmox cluster consisting of two Dell R340 and one Intel NUC. There are 25 VM’s across all three machines. They do various development duties along with home assistant, plex, and Blue Iris. The rack lives in a closet under the stairs and I have fiber ran to my office. We did a massive renovation when we purchased so I wired the entire house since the walls were all opened. Average power draw is around 480 watts.
Here is a picture of the rack back when it was all R330. Those have since been sold and upgraded to R340. I added vents during the renovation. Inlet temps stay around the house ambient, and exhaust is about 20 degrees F hotter. I cover the front with additional sound baffles to better route fresh air and control noise. Its pretty much silent outside the closet.

This is the patch panel. I have perimeter cameras all the way around the house plus more than enough wifi access points. Each room also got 2x ethernet on each side, 4x total. My office has got 6x ethernet plus 4x fiber and a 2-inch conduit to pull whatever else I can think of later.

I use Grafana and custom-made scripts for monitoring and alerting. Most of the infrastructure is automated with scripts. One of these days Ill learn Ansible but I really enjoying just figuring it all out. This isn’t my job I just do it for fun. Here is the dashboard I run on one of my desk monitors.

I run my hobby websites, and my Lemmy instance, in the colo but its primary purpose is to be an offsite backup. Proxmox backup server performs best on SSD hence the large array. I also do a lot of travel for work so that’s my remote dev machine too. I run my own mail servers with some small VPSs acting as SMTP and IMAP bouncers to internal servers at home and in the colo working in parallel. HA proxy does the bouncing for high availability and dovecot and postfix do the heavy lifting with solr providing lighting fast search. I do use a third party for outbound mail for better deliverability.
Dell R350 - Colo Proxmox
- Intel E-2388G processor
- 128gb 3200 ECC ram
- Dell H755p raid
- 8x Crucial MX500 4TB in raid 6
- Samsung 990 2TB NVMe

Dell R340 - Proxmox Node 0
- Intel E-2278G processor
- 128gb 3200 ECC ram. Despite the spec sheets and irdrac saying these only support 64gb they run 128gb just fine.
- Ultrastar DC SN640 7.68TB NVMe
- Dell H810 Flash with LSI firmware. HBA for SC200 disk shelves.
- Mellanox CX354A @ 40GbE

Dell R340 - Proxmox Node 1
- Intel i3-9100T processor
- 64gb 2400T ECC ram
- Ultrastar DC SN640 7.68TB NVMe
- Intel X520-DA2 @ 2x 10gbe

Intel 7th Gen Nuc - Proxmox Node 2
- Intel i5-7260U processor
- 32gb 2400 ram
- Ultrastar DC SN640 7.68TB NVMe

This is mounted to the wall under my desk in a silent case. I use Verizon Wireless home internet as a backup and this server is the router. My entire closet rack can go offline and Ill still have internet access.

Dell R730 - GPU
- 2x Intel E5-2696 V4 processor
- 512gb 2400T ECC ram
- SanDisk Skyhawk 3.84TB NVMe
- 2x Nvidia P100 16gb GPU
- Intel X520-DA2 @ 2x 10gbe
- This one stays powered off when not in use. I built it to play around with tensorflow and AI but haven’t had much time.

Dell SC200 Disk Shelf 1
- 12x WD 8TB 5400 rpm shucked drives
- Single z2 pool
- Roughly 74 usable TB
- Cold backups of the primary array. Only powered on once a month to sync.
Dell SC200 Disk Shelf 2
- 12x HGST 10tb SAS drives
- 2x z2 pools
- Roughly 72 usable TB
- Primary storage array. Sitting at about 70% utilized so its time to upgrade.

My setup is a mix of on-prem and VPS.
On-Prem
- Primary Cluster (24 cores, 192 GB RAM, 36 TB usable storage)
- Two Dell R610 (12 cores, 96 GB RAM each)
- vSphere 7.0, ESXi 6.7 (because processors are too old for 7.0)
- Kubernetes 1.24
- Single controller VM
- Two worker VMs
- OS: Ubuntu 20.04
- K8s Flavor: Kubeadm
- Use: Almost everything
- Storage:
- Synology 1515 (11 TB usable, RAID 5) - vSphere datastore via NFS
- Synology 1517 (25 TB usable, RAID 5) - Kubernetes mounts via NFS, media, general NAS stuff
- Standalone Node (4 cores, 16GB RAM, 250 GB SSD)
- Lenovo M900 micro-PC
- OS: Ubuntu 22.04
- Kubernetes 1.24
- K8s Flavor: k3s
- Use: provide critical network services (DNS/DHCP) if any part of the complex cluster goes down, Frigate due to USB Coral TPU plugged in here
- Networking / Other
- DNS:
- Primary: AdGuard Home running on Standalone
- Internal domain: BIND VM running in Primary Cluster
- Firewall: Juniper SRX 220H
- Switch: Juniper EX2200-48
- WiFi: 3x Unifi In-Wall APs
- Power:
- UPS backing compute and storage (10-15 min runtime)
- UPS backing networking gear (15-20 minute runtime)
- DNS:
VPS
- Single Linode (2 cores, 4 GB RAM, 80 GB storage)
- OS: Ubuntu 22.04
- Kubernetes 1.24
- K8s Flavor: k3s
- Use: UptimeKuma to monitor on-prem infrastructure, services that can’t go down due to home ISP or power issues (like family RocketChat).
Every service (except Plex) is containerized and running in Kubernetes. Plex will be migrated soon™. Everything in Kubernetes is handled via Infrastructure as Code using FluxCD and GitOps principles. Secrets are stored in git using Mozilla SOPS for encrypt/decrypt. Git repos are currently hosted in GitHub, but I’m considering Gitea, though that might present a bit of a bootstrapping problem if all the infrastructure that hosts Gitea is declared inside Gitea…

Git repos are currently hosted in GitHub, but I’m considering Gitea …
I have a similar-ish setup to this and landed on having Gitea hosted outside the cluster using plain docker-compose along with renovate for dependency updates within the cluster. These two containers configuration files live on Github and have Github’s renovate-bot keep them up to date. Changes get picked up through polling the git repo and applied to the host through Portainer, though I’m planning to swap that out with a slightly more complex solution relying solely on Gitea’s new CI/CD tooling.
- Primary Cluster (24 cores, 192 GB RAM, 36 TB usable storage)

Host os is debian 11 . My containers look like this.
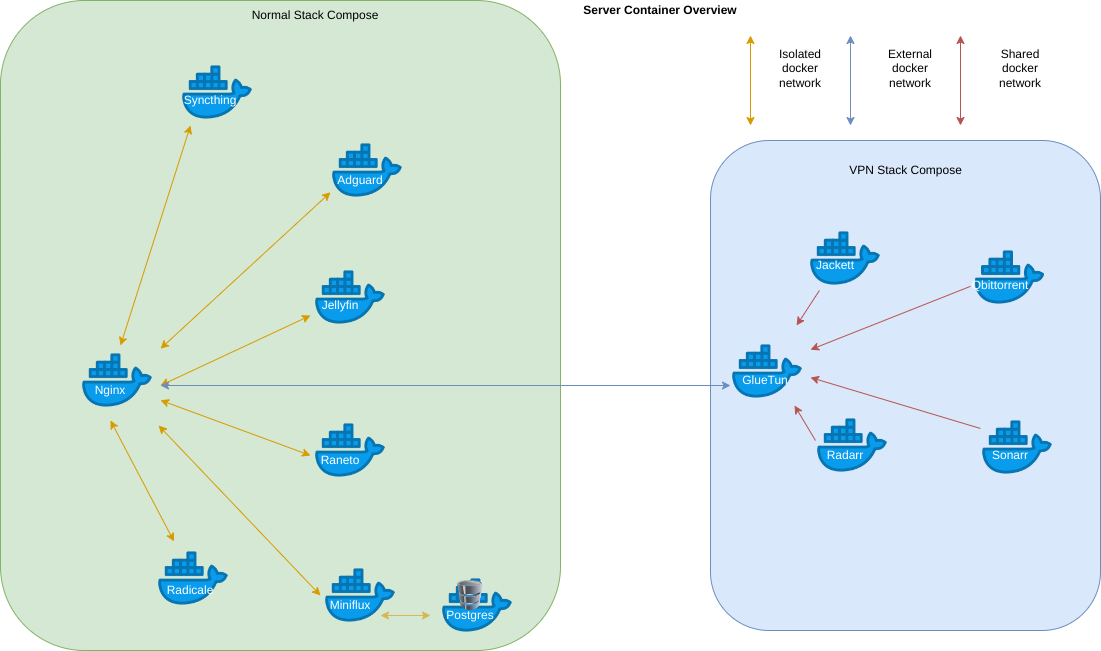
I run everything on local hardware. 1 Synology NAS, one old desktop (Ryzen 5 5600X) which has been repurposed to a Proxmox node, and a second Proxmox node (i5-6500T). I use Open Media Vault with Docker as my primary host, and I have a CoreOS secondary host that I have a couple of Podman containers on. I’m planning moving stuff to Podman eventually, but I was mostly focused on moving the bare metal OMV host to a vm recently. I have a media share on my NAS that some containers rely on. I also have a NFS share on it that I use for larger data pools (like nextcloud, download folders for torrents).
- Everything is: Bare metal Proxmox -> VMs -> Containers. No services running directly
- I use Docker (mostly) and a couple of podman containers, moving to podman going forward
- Only orchestration is docker-compose (for docker) and systemd (for podman)
- No central log server, haven’t needed one
- Uptime Kuma for monitoring, a few services ping me on telegram with stuff they are doing via a bot there.
I have 3 servers other than my laptop: two “1-liter” ultra small form factor PCs from HP and Dell, and a Dell small form factor. Roughly, they’re my personal / desktop virtualization / dev server, my webserver, and my data store.
Everything is containers on top of Proxmox, mostly VMs but a few LXC containers as well.
Most of it runs some flavor of Debian.
A number of the services are reverse proxied thru a $5/mo VPS.
Internet access is via 24/7 VPN thru a similar $5/mo VPS.
I have a Turing Pi v2 but only one of the slots populated with an 8gb pi (because I can’t buy any more right now). Currently just running an SMB share and paperless (in docker) but I plan to add more and use k3s or docker swarm once I have an actual cluster. I am also yet to set up any log handling or monitoring but that’s on the todo list.

I have an HP DL380 Gen8 and then a PC I bought from the local university and use as a server.
My DL380 runs ESXi. My PC runs Ubuntu on bare metal.
All of my apps are either fully VM-based (Home Assistant OS) or run in containers. Containers are far easier to build, upgrade, and migrate, and also make file management a lot easier.
I use Docker Compose. No Swarm or Kubernetes at this point.
Hopefully this is at least a good start! Let me know if you have any questions.
Yeah, that’s great! I’ve got an old HP desktop that a family member discarded that will be the start of mine.
Do you use a single docker-compose.yaml file for an entire machine, or docker-compose files per-app?
A combo of both. I group all my media apps like Sonarr, Radarr, SABnzbd, etc together in one compose since I consider each of them to be a part of the same “machine”, but most of my apps have their own compose.

I have a single ASUS Chromebox M075U I3-4010U which I use as a Docker host. It’s neatly and inconspicously tucked away under my TV, and it’s quiet even when the fan’s on full if a heavy workload is running.
Main Specs:
- Processor: Intel Core i3-4010U 1.7 GHz
- Memory: 4 GB DDR3 1600 (I upgraded this to 16 GB)
- Storage: 16 GB SSD (I upgraded this to 64 GB)
- Graphics: Intel HD Graphics 4400
- OS: Google Chrome OS (Currently running Ubuntu 22.04)
Full Specs: https://www.newegg.ca/asus-chromebox-m075u-nettop-computer/p/N82E16883220591R
I started off with a single-node Kubernetes cluster (k3s) a few years ago for learning purposes, and ran with it for quite a long time, but have since gone back to Docker Compose for a few reasons:
- Less overhead and more light-weight
- Quicker and easier to maintain now that I have a young family and less time
- Easier to share examples of how to run certain stacks with people that don’t have Kubernetes experience
For logs, I’m only concerned with container logs, so I use Dozzle for a quick view of what’s going on. I’m not concerned with keeping historical logs, I only care about real-time logs, since if there’s an ongoing issue I can troubleshoot it then and there and that’s all I need. This also means I dont need to store anything in terms of logs, or run a heavier log ingestion stack such as ELK, Graylog, or anything like that. Dozzle is nice and light and gives me everything I need.
When it comes to container updates, I just do it whenever I feel like, manually. It’s generally frowned upon to reference the
latesttag for a container image to get the latest updates automatically for risk of random breaking changes. And I personally feel this holds true for other methods such as Watchtower for automated container updates. I like to keep my containers running a specific version of an image until I feel it’s time to see what’s new and try an update. I can then safely backup the persistent data, see if all goes well, and if not, do a quick rollback with minimal effort.I used to think monitoring tools were cool, fun, neat to show off (fancy graphs, right?), but I’ve since let go of that idea. I don’t have any monitoring setup besides Dozzle for logs (and now it shows you some extra info such as memory and CPU usage, which is nice). In the past I’ve had Grafana, Prometheus, and some other tooling for monitoring but I never ended up looking at any of it once it was up and “done” (this stuff is never really “done”, you know?). So I just felt it was all a waste of resources that could be better spent actually serving a better purpose. At the end of the day, if I’m using my services and not having any trouble with anything, then it’s fine, I don’t care about seeing some fancy graphs or metrics showing me what’s going on behind the curtain, because my needs are being served, which is the point right?
I do use Gotify for notifications, if you want to count that as monitoring, but that’s pretty much it.
I’m pretty proud of the fact that I’ve got such a cheap, low-powered little server compared to what most people who selfhost likely have to work with, and that I’m able to run so many services on it without any performance issues that I myself can notice. Everything just works, and works very well. I can probably even add a bunch more services before I start seeing performance issues.
At the moment I run about 50 containers across my stacks, supporting:
- AdGuard Home
- AriaNG
- Bazarr
- Certbot
- Cloudflared
- Cloudflare DDNS
- Dataloader (custom service I wrote for ingesting data from a bunch of sources)
- Dozzle
- FileFlows
- FileRun
- Gitea
- go-socks5-proxy
- Gotify
- Homepage
- Invidious
- Jackett
- Jellyfin
- Lemmy
- Lidarr
- Navidrome
- Nginx
- Planka
- qBittorrent
- Radarr
- Rclone
- Reactive-Resume
- Readarr
- Shadowsocks Server (Rust)
- slskd
- Snippet-Box
- Sonarr
- Teedy
- Vaultwarden
- Zola
If you know what you’re doing and have enough knowledge in a variety of areas, you can make a lot of use of even the most basic/barebones hardware and squeeze a lot out of it. Keeping things simple, tidy, and making effective use of DNS, caching, etc, can go a long way. Experience in Full Stack Development, Infrastructure, and DevOps practices over the years really helped me in terms of knowing how to squeeze every last bit of performance out of this thing lol. I’ve definitely taken my multi-layer caching strategies to the next level, which is working really well. I want to do a write-up on it someday.
I’ve got a mix of hosting environments personally. A dedicated box hosted with Hetzner (their auction prices can be pretty decent) plus a Pi 4 and an old NAS for internal services. Docker containers used for pretty much everything - mostly set up with a big ol’ /opt/ folder with a bunch of service specific folders with docker-compose.yml files and bind mounts galore. Got a wireguard VPN bridging between then because that seemed sensible.
Running Portainer for some extra management and monitoring, then a bundle of stuff:
- Mailcow for email
- Owncloud for for sync and storage
- Phototropism
- Bitwarden
- Emby for media playback
- NextPVR for recording
- Private instances of Pleroma and Lemmy
- A slightly broken telegram/grafana stack with some container monitoring stuff hooked in
- The odd dedicated game server when the need arises … and some things I’ve forgotten about.
Got a spare old i5 machine around set up to auto hook into Portainer if I need some extra grunt at some point, but it’s more likely to be used when I can’t be bothered paying for the dedicated box.
Aware a lot of it’s suboptimal, but it’s easy to work with and familiar, and that’s enough to make it workable.

I have four small computers that are the nodes, with a TerraMaster NAS for hosting the data.
I run Proxmox on all four nodes in a cluster. I’ve been moving things around in hopes of switching the hosts over to ZFS so two of the nodes currently don’t have anythig on them. Eventually they will set up for HA fail over (the main driver for switching to ZFS). I have one VM running Yunohost. I have server LXC containers for some services and a couple running Docker that host the rest of the services. Basically as I found things I was interested in it was just easier and quicker to start with Docker. I’ll probably move everything over to Podman and ditch the LXC containers and the VM. All in due time.
As for the hardware itself:
- Node 1: Lenovo m93p: Core i5-4670 @ 3.4GHz; 16GB RAM; 256GB m.2 SSD
- Node 2: Lenovo m93p: Core i5-4570T @ 2.9GHz; 16GB RAM; 256GB m.2 SSD
- Node 3: Gigabyte Brix: Celeron J4105 @ 1.5GHz; 16GB RAM; 500GB m.2 SSD
- Node 4: Trigkey Green G3: Celeron N5095 @ 2.9GHz; 16GB RAM; 500GB m.2 SSD
- NAS: TerraMaster TNAS-5670. It has 2 drive bays with 2TB drive in each.
So far only a few items are accessible outside local network, those are hosted on the Yunohost VM. I am still learning how to set up a good reverse proxy and authentication. Once I get that figured out I will push for all Podman containers. I’m thinking about making use of ansible for “orchestration” with docker-compose files. Currently I don’t monitor anything or collect logs.
You might check our Authentik for the authentication bit. It’s kinda complex, but can do proxy auth, OIDC, SAML, and LDAP.
I’ve seen Authentik mentioned. I’m currently thinking about trying out Cosmos-Cloud.io. it has everything built in and runs on docker. I doubt I’ll stay without since the licensing is ambiguous at the moment.
I would probably not do what I do.
I have two machines that host everything I use, a Thinkpad x220 (i5-2540M, 8GB RAM) which lives on the floor near my router, and an RPI4 (4GB) which lives next to my router on the table. Which one does what usually is dictated by what machine I happen to SSH into. The RPI4 is attached to an 8TB Easystore I originally bought to shuck but didn’t, and wears a NAS hat. Soon-ish I’ll probably get some extra drives and set up a “proper” server which is less trepidatious.
I run almost everything I use in containers, and Podman is my container engine of choice. Originally it was because Fedora made me, but now I am a big Podman fan.
Logging and updates are not something I like to talk about because I handle both poorly, and normally just let her rip. I do updates weekly or so whenever I get around to it, but logs are a wasteland. I’d like to get a good monitoring system set up, but for me it feels like way more work than running the things I actually want and use, so I usually end up just letting them accumulate on the disk and grep them whenever I need to.