- cross-posted to:
- opensource@lemmy.ml
- firefox@fedia.io
- linux@lemmy.ml
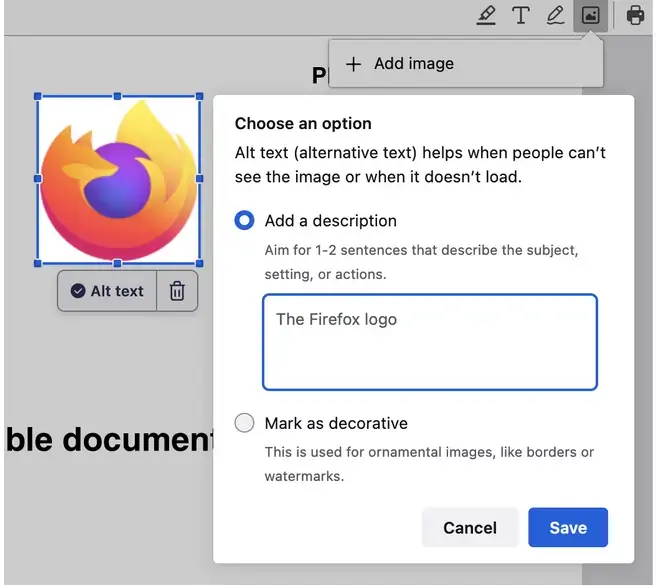
New accessibility feature coming to Firefox, an “AI powered” alt-text generator.
"Starting in Firefox 130, we will automatically generate an alt text and let the user validate it. So every time an image is added, we get an array of pixels we pass to the ML engine and a few seconds after, we get a string corresponding to a description of this image (see the code).
…
Our alt text generator is far from perfect, but we want to take an iterative approach and improve it in the open.
…
We are currently working on improving the image-to-text datasets and model with what we’ve described in this blog post…"


So, planned experimentation and availabiltiy
Sounds like a good plan.
While a reasonable size for Laptop and desktop, the couple of seconds time could still be a bit of a hindrance. Nevertheless, a significant unblock for blind/text users.
I wonder what it would mean for mobile. If it’s an optional accessibility feature, and with today’s smartphones storage space I think it can work well though.
They list 5 positives about using local models. On a blog targeting developers, I would wish if not expect them to list the downsides and weighing of the two sides too. As it is, it’s promotional material, not honest, open, fully informing descriptions.
While they go into technical details about the architecture and technical implementation, I think the negatives are noteworthy, and the weighing could be insightful for readers.
An array of pixels doesn’t make sense to me. Images can have different widths, so linear data with varying sectioning content would be awful for training.I have to assume this was a technical simplification or unintended wording mistake for the article.I imagine it’s a 2D array? So width would be captured by uhh like
a[N].len.It could be I’m misunderstanding you, because not not sure what you mean by:
Looking at Wikipedia on arrays, I think I’m just not used to array as terminology for multi-dimensional data structures. TIL
Might be a significant issue if more applications adopt these kind of festures and can’t share the resources in a meaningful way.