
If they were just talking about Reddit, I’d assume something dodgy was going on connected with the IPO. But Quora is supposedly back from the dead too… Am I missing something glaringly obvious here?

They are probably paying clickfarms.
Reddit probably isn’t, as that would be cooking their metrics and Huffman would get fucked by the long arm of the SEC. They might still be, Huffman loves Elon and Elon got away with tons of shit.
Advertisers are probably paying more content farms to astroturf it though.
Plus without the API, do you really think people just stopped scraping Reddit? They just run a headless Chrome instance now and I bet Reddit doesn’t look the gift horse of traffic in the mouth.

Advertisers are probably paying more content farms to astroturf it though.
Yup, in fact we just banned ~13 accounts tonight from a subreddit I’m still involved with. That’s just the ones we identified, and it’s only a medium sized subreddit
A user noticed that the responses to a post sounded a little off and reported it. Turns out there was a network of bots using generative AI to mix real academic advice (ex. “Go talk to the advising office”) with occasional subtle advertisements (ex. “I recommend using grammarly and (advertised service)”.
Once we caught on, we looked through the history of those accounts and gathered as many as we could identify and banned them all.
I don’t think this is Reddit’s doing, and they’re usually good about banning spam bots site wide once a mod report is made. Still, they benefit from increased activity and they have an incentive to do less of that. It was also much harder to notice the problem because of the AI generation. If a user didn’t explicitly report it, I probably wouldn’t have noticed
This is going to be the Idiocratizing of the internet. AI is going to be training in itself with these unidentified posts and get dumber and dumber.
Let’s hope no one lets it have access to anything important…
It feels a little like how steel from before above ground nuclear testing, called low-background (or pre-war) steel because it isn’t contaminated is prized for building some sensors.
Pre AI information need to be preserved, otherwise we might not really know if the info we’re seeking is fact based in any way.

This is going to be the Idiocratizing of the internet.
93/94 was when I first got AOL on a 14.4k modem. I’m one of those shitty users!
We used to use gopher and college FTP sites to download warez as a freshman in HS, and then moved on to Hotline trackers.

Except I can totally see them committing securities fraud in order to pump up the numbers. It seems very much like something they would do.
I think that’s what this part of the comment was about:
They might still be, Huffman loves Elon and Elon got away with tons of shit.

The SEC got its funding slashed by Trump - are they like the IRS now where they don’t have the resources to truly do the job anymore?

The API is not gone, and is still free for both “for non-commercial researchers and academics under our published usage threshold” and “for moderator tools and bots”
https://www.redditinc.com/blog/apifacts
There are several ways to add your personal API key to (modified) final versions of Sync, Relay, Infinity, and even Apollo on iOS to be able to continue to use those clients, however Reddit has changed how Reddit links work, so those methods are becoming more and more broken.
Did you guys read the article? It’s all about how since google and Reddit penned a deal to use Reddit to train google AI models, google is now massively pushing Reddit links in search results.
And their answer, ironically, is to avoid “Gen-AI garbage.”
But you should really read the article. It pissed me the fuck off. Because that sounds…massively illegal.
I wonder if Reddit user activity has noticeably increased. Probably not.
Like, this will help Reddit in the short term, and honestly is a good idea from a search perspective (how many queries have I manually appended “Reddit” to?), but it doesn’t necessarily help with the fundamentals of the platform.
You scratch my back, I scratch yours
I think I’ve comment this before but over the pandemic years I did a little experiment. Every day I bookmarked the obvious content reposting bot accounts on the first few pages of r/all. After a while I checked back on the accounts. The majority of them become cryptocurrency spam bots. A very small percentage spam random things. There was an extremely high success rate of picking out the bot accounts. Pretty much all them were except for maybe a handful.
spez is basically exit scamming with reddit. Whoever is buying the dataset is getting robbed blind. That’s if reddit inc isn’t being upfront behind closed doors. Maybe they are. After all reddit does have well over a decade of mostly organic activity. The recent data has to be absolute trash though.
It isn’t like you can’t otherwise get the older data if you really want though, pretty sure it’s on torrents. The newer stuff is all they have to sell.
As someone who still semi-frequents reddit, it’s mostly bots, more and more of which are clearly using some form of ChatGPT or another LLM. It’s actually kinda absurd, I’ve seen many a comment chains where it’s just different bots replying to each other, both pretending to be real people.
If bots actually do start frequenting Reddit, and they get hard to detect, the AI content generation will start poisoning itself. Isn’t that cool?
For me, the cool part is that the vast majority of people can’t tell anything has changed.
Also, we can be rather poisonous ourselves.
It’s sort of become a bit of a meme to end every google question with ‘reddit’ to trick it into showing you an actual human response. I’m sure that’s been good for traffic

I’ve had to start limiting the date to pre-2023 to keep ai bs out of the results
Just add
before:2023to your search query BTW.Thank you!
Add what? Didn’t show up on mobile
add “before:2023” to your search query
That’s an excellent tip! I draw occasionally and finding references for animals is so much worse than it used to be.

I’ve heard some AI experts on Hard Fork suggest 80% of the Internet will be AI bot trash in 2 years.
Honestly wouldn’t surprise me. There’s already so much garbage when you google pretty much anything
Subs picked to be “mainstream” get botted to death and every other sub is half dead, so not really. Quality fell off a cliff.

Simplest explanation is that the general public doesn’t give a shit and while Facebook is on the downturn (not sure if numbers can back that up) people need to go somewhere else. Maybe that is reddit right now, they got the marketing and content to get people on it.
Fuck me, I’m not even using Google directly, I’m currently on MetaGer which is a meta search engine, and even there, I got annoyed today already that half the top links were shitty Reddit links.
I hate this shit so much. I work as a Software Engineer, so using web search was half our work day a few years back.
Personally, I’m thankfully already at a point where I can figure out most things by fucking around. But we have an intern who’s new to the job and she regularly tells me that she struggles to find anything useful on the rather mainstream technologies that we’re using.To some degree, LLMs are still a workaround for that, but they won’t be able to update to newer information without pulling in LLM spam, so either we’re stuck with the current technologies for the foreseeable future or we won’t have a way of finding anything in a few years.
And the worst part is that I can’t think of a real solution. Maybe we could use a search engine, which only queries official documentation directly. That could be an improvement, as often not even that shows up in the normal search results. But really, what our intern needs is tutorials and those are virtually indistinguishable from LLM spam…
Official documentation can, sadly, only contain so much information. Lots of tools are community driven and there are some niche uses of libraries that official docs don’t know about, or including them would just take up space.
Yeah, for sure. I’m mostly saying that she sometimes struggled to even just find an appropriate Hello World example, to the point where she would ask me for help after a while.
Then I, having already gotten used to the terrible search engine results, opened the official documentation directly and had it after a handful of clicks.Obviously, she understood pretty quickly, but the official documentation doesn’t always have a built-in search and can be difficult to navigate, so that’s why I’m saying even just a search engine for that could be good…

Taking a cursory look I feel like posts still aren’t being engaged with like they used to. I remember seeing posts with 100,000 upvotes very regularly on the front page, but you really don’t see that anymore. Yeah maybe they tweaked their calculations but why make your site look like it’s not as engaging as before right before a major IPO offer?

Google has massive swing; there’s a whole industry around getting Google to prefer your low quality crap nobody wants to see over others’ low quality crap nobody wants to see.
If Google has finally figured out a metric to measure “helpfulness” of a website and punishes unhelpful websites, a bunch of dogshit that would have otherwise gotten top spots may have been banished to page 2.
Reddit results would naturally creep up because of that (and therefore get a lot more clicks), even if they didn’t change at all.
I actually have noticed a lot more Reddit in my search results recently.

Part of it is either Reddit manipulating search positioning or Google (most people’s default search) prioritizing Reddit results. Searching for answers to questions often results in a half page of Reddit links. They may not be relevant, but that doesn’t become apparent until you’re there.

ewh google
If you read the linked article it’s the latter. They explicitly say Google changed their algorithm and reddit consistently ranks at the top now. Even over the articles which the reddit thread is about.

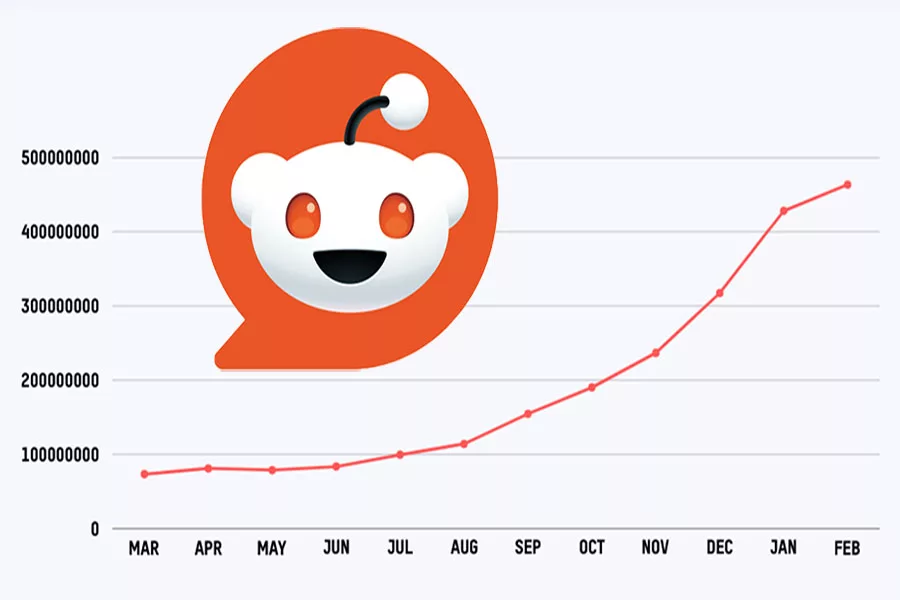
The growth trend according to Google Trends indicates that it is still growing, but definitely not a quadrupling over 6 months.
Ai generated content
Bots all the way down

Wasn’t it that (they want to) offer a way to get money for your karma points?