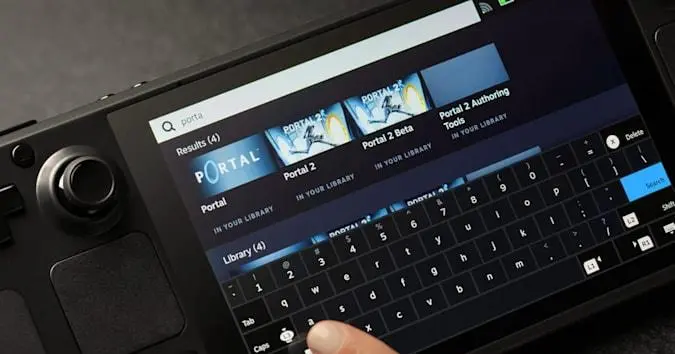

Interesting decision

I feel like this is less of a big decision and more of a ‘duh’ sort of situation. To my understanding this isn’t saying that all AI art violates copyright, but that AI art which does violate copyright can’t be used.
Like if i took a picture of Darth Vader and handed it to NightCafe to fool around with, that still belongs to Disney. Steam is legally required to act if a valid DMCA is sent, and to adhere to the court’s ruling in the case of a dispute.
I feel like this is a reassurance that they intend to obey copyright law rather than a restriction of all AI art. Basically they’re saying that if you DMCA someone in good faith on the basis of derivative works, they’ll play ball.
Right, the phrasing is “copyright-infringing AI assets” rather than a much more controversial “all AI assets, due to copyright-infringement concerns.”
I do think there’s a bigger discussion that we need to have about the ethics and legality of AI training and generation. These models can reproduce exact copies of existing works (see: Speak, Memory: An Archaeology of Books Known to ChatGPT/GPT-4).
Sure, but plagiarism isn’t unique to LLMs. I could get an AI to produce something preexisting word for word, but that’s on my use of the model, not on the LLM.
I get the concerns about extrapolating how to create works similar to those made by humans from actual human works, but that’s how people learn to make stuff too. We experience art and learn from it in order to enrich our lives, and to progress as artists ourselves.
To me, the power put into the hands of creators to work without the need for corporate interference is well worth the consideration of LLMs learning from the things we’re all putting out there in public.
That’s a fair point.
In my eyes, the difference is the sheer volume of content that these models rip through in training. It would take many, many lifetimes for a person to read as much as an LLM “reads,” and it’s difficult to tell what an LLM is actually synthesizing versus copying.
Now, does it really matter?
I think the answer comes down to how much power is actually put into the hands of artists rather than the mega-corps. As it stands, the leaders of the AI race are OpenAI/Microsoft, Google, and Meta. If an open LLM comes out (a la Stable Diffusion), then artists do stand to benefit here.
I mean, they are and they aren’t. OpenAI, Google, and Meta may be in control of the most popular iterations of LLMs at the moment, but the cat’s also kind of out of the bag. If we all lost access to ChatGPT and other AI stuff that’s dependent on it over-night, there’s a pretty huge incentive to fill that gap.
They control it now because they’ve filled people’s emerging need for LLMs to assist in their workflow. If they try to choke that off as though they own it in a wider sense, they’re going to find their power over it turning to ash in their mouths and someone else will take their place.
I’m optimistic that the trend of cracks developing in the authoritarian power structures we’re seeing on the internet won’t stay limited to there. LLMs could be a big part of that. Even just Stable Diffusion being Open Source is massive. I’m sure others will follow, and those big companies, if they’re smarter than Elon and Spez, will want to hang onto their relevance as long as possible by not shunting users over to FOSS.
Absolutely true. StableLM is a thing, and although it’s not as good as ChatGPT or even Bard, it’s a huge step. I’m sure there will be better free models in the months and years to come.
It’s not unique to LLMs, but the issues are always the same: how to check if there is plagiatism, and who to blame.

I just don’t see how this is different from “Valve won’t publish games that feature copyright-infringing assets” which is probably already true. Does it matter whether a human or an “AI” produced it?
Probably not. But there is a pretty widespread belief that images generated by AI cannot possibly be infringing, because the model is somehow inherently transformative.
This is not the case, and Valve reiterating that it is not the case might keep developers who are under the impression above from trying.
I have mostly ever seen the exact opposite position: that AI cannot possibly produce anything not copyright infringing. It’s hard to remember a time someone was claiming that a given artwork produced by AI could never be copyright infringing except among like, cryptobros.

Valve was also the company to ban games from Steam, that made use of NFT and Crypto Currencies. While at the same time Epic Games publicly defended NFT and said they can publish their games on their platform. I wonder if the same will happen with AI asset flip games.
I’m just worried how to detect AI assets.
I don’t think any platforms banning use of AI assets is really thinking about enforcement at the moment. I think this is more of a “CYA” type of thing for them since AI-generated stuff is still legally fuzzy. It’s just so that if any AI-generated content is deemed a violation of some IP law, Valve can’t be held liable.
Ah I understand and it makes sense now. Valve does what it can do, so it complies with the law. If they know about a violation, then Valve has to take action.

it’s easy to detect AI assets because they look like shit. check the new hawken rerelease for an easy example.
Ehh, that depends on the person working with the AI and how they’re using it. If you use something like Stable Diffusion to punch up traditional art, you can get some great results. Not always perfect, but more than enough to make something really nice really quickly if you have a little experience with both sides.
Personally, it’s enabled me to produce mod assets for a game server I’ve been working on extremely rapidly with fantastic results. But if i didn’t have experience with graphic design or was just starting out with AI assisted art then yeah, it’d probably look a lot more wonky.

I imagine a lot of companies will take the same stance until there’s some sort of ruling or law clarifying the issue. Valve doesn’t have anything to gain by allowing it, so it makes sense to block it.
This could change based on the outcome of the class action lawsuit pending against Midjourney and Stable Diffusion.
I think in the future companies would have to use tools that can have model data set exported. So they can be verified and not getting dinged/blocked.
I don’t think so. Copyright doesn’t extend to styles, and I think the courts will figure that out eventually.
It does NOT, but the model network wouldn’t be what it is without the training data. So they either need to start retrain a “clean” version, or risk delay and could invalidate all the related works that derived from the model trained by scraped data…
Human artists don’t start with a clean version… They’re trained on copyright material all the time without permission.
There is a big difference though. Human artist train with existing ones and strive to understand what technique is used then trying to come up with their own style. If you read manga you will see the trails of author that was trained under another/copy style but then go off to their own, Jojo is a fantastic example. Human artists likes to come up with their own.
Where AI use the training data to do the derive work use like devian/instagram artist names as prompt weight. There are no citation like in journal, there are no recognition in like “I tried to copy this artist’s style and experiment with this color pallet”. And lastly, many artist sued because their stuff are used as training material without any consulting from the hosting site, sites abuse the term of use and then jump on the AI train(some are simply getting scraped). It’s a big damage to the art sharing community and AI model development/training.
If you don’t like the future where all the image on internet has watermark plastered all over the image(I know AI can also try to remove watermark), there needs to be a formal established relationship between artists and AI models.
Legally the difference is not as big as you think it is.
Also your argument about damage is pretty weak. The automated loom did a ton of damage to weavers, gasoline engines did a ton of damage to horse ranchers, computers(electronic) did a lot of damage to computers (that’s what humans that performed calculations for a living were called)
As a consumer of art, I don’t really care if a computer or a person made it. I’m buying it because I like the look, not the person or process. I know other people who do care, but other people like craft beer too.
By damage I mean the progress of the tech, not the economical damage generative AI model could bring. That’s why I list both. When your process betray the trust of community, it just going to make it even harder to progress now that it has that tainted reputation. Artists wants recognition simple as that, yes they like the money too but it comes from recognition.
I know a lot of artist(source: I work in creative industry) likes experiment with AI arts to speed up their process, now that this becomes kinda of taboo I see less post of their experiment. It also delays the progress of meaningful workflow like using AI to patch texture flaws, generate better patterns to mix with existing one, if they really want to use it to generate character/prop textures for games, now they can’t. It’s not just games, it could bleed into many other area.( Film/TV/Anime/Manga’s production now have to think carefully so they don’t get sued. )
I half-agree.
I do think that companies should clarify how they’re training their models and on what datasets. For one thing, this will allow outside researchers to gauge the risks of particular models. (For example, is this AI trained on “the whole Internet,” including unfiltered hate-group safe-havens? Does the training procedure adequately compensate for the bias that the model might learn from those sources?)
However, knowing that a model was trained on copyrighted sources will not enough to prevent the model from reproducing copyrighted material.
There’s no good way to sidestep the issue, either. We have a relatively small amount of data that is (verifiably) public-domain. It’s probably not enough to train a large language model on, and if it is, then it probably won’t be a very useful one in 2023.